For a while now I’ve been wondering about what might be the minimal set of technologies that allows me to tackle the widest range of projects. The answer I’ve arrived at, for backend development at least, is GraphQL and ArangoDB.
Both of these tools expand my reach as a developer. Projects involving integrations, multiple clients and complicated data that would have been extremely difficult are now within easy reach.
But the minimal set idea is that I can enjoy this expanded range while juggling far fewer technologies than before. Tools that apply in more situations mean fewer things to learn, fewer moving parts and more depth in the learning I do.
While GraphQL and ArangoDB are both interesting technologies individually, it’s in using them together that I’ve been able to realize those benefits; one of those moments where the whole is different from the sum of it’s parts.
Backend Minimalism
My embrace of Javascript has definitely been part of creating that minimal set. A single language for both front and back end development has been a big part of simplifying my tech stack. Both GraphQL and ArangoDB can be used in many languages, but Javascript support is what you might describe as “first among equals” for both projects.
GraphQL can replace, and for me has replaced, server side frameworks like Rails or Django, leaving me with a handful of Javascript functions and more modular, testable code.
GraphQL also replaces ReST, freeing me from thinking about HATEOAS, bike-shedding over the vagaries of ReST, or needing pages and pages of JSON API documentation to save me from bike-shedding over the vagaries of ReST.
ArangoDB has also reduced the number of things I need to need to know. For a start it has removed the “need” for an ORM (no relational database, no need for Object Relational Mapping), which never really delivered on it’s promise to free you from knowing the underlying SQL.
More importantly it’s replaced not just NoSQL databases with a razor-thin set of capabilities like Mongodb (which stores nested documents but can’t do joins) or Neo4j (which does joins but can’t store nested documents), but also general purpose databases like MySQL or Postgres. I have one query language to learn, and one database whose quirks and characteristics I need to know.
It’s also replaced the deeply unpleasant process of relational data modeling with a seamless blend of documents and graphs that make modeling even really ugly connected datasets anticlimactic. As a bonus, in moving the schema outside the database GraphQL lets us enjoy all the benefits of a schema (making sure there is at least some structure I can rely on) and all the benefits of schemalessness (flexibility, ease of change).
Tools that actually reduce the number of things you need to know don’t come along very often. My goal here is to give a sense of what it looks like to use these two technologies together, and hopefully admiring the trees can let us appreciate the forest.
Show me the code
First we need some data to work with. ArangoDB’s administrative interface has some example graphs it can create, so lets use one to explore.
If we select the “knows” graph, we get a simple graph with 5 vertices.
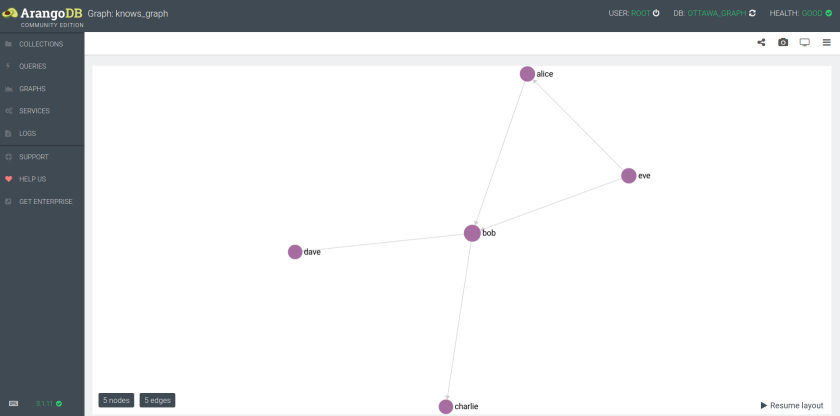
This graph is going to be the foundation for our little exploration.
Next, the only really meaningful information these vertices have is a name attribute. If we are wanting to create a GraphQL type that represents one of these objects it would look like this:
let Person = new GraphQLObjectType({
name: 'Person',
fields: () => ({
name: {
type: GraphQLString
}
})
})
Now that we have a type that describes what a Person object looks like we can use it in a schema. This schema has a field called person which has two attributes: type, and resolve.
let schema = new GraphQLSchema({
query: new GraphQLObjectType({
name: 'Query',
fields: () => ({
person: {
type: Person,
resolve: () => {
return {name: 'Mike'}
},
}
})
})
})
The resolve is a function that will be run whenever graphql is asked to produce a person object. type is a type that describes the object that the resolve function returns, which in this this case is our Person type.
To see if this all works we can write a test using Jest.
import {
graphql,
GraphQLSchema,
GraphQLObjectType,
GraphQLString,
GraphQLList,
GraphQLNonNull
} from 'graphql'
describe('returning a hardcoded object that matches a type', () => {
let Person = new GraphQLObjectType({
name: 'Person',
fields: () => ({
name: {
type: GraphQLString
}
})
})
let schema = new GraphQLSchema({
query: new GraphQLObjectType({
name: 'Query',
fields: () => ({
person: {
type: Person,
resolve: () => {
return {name: 'Mike'}
},
}
})
})
})
it('lets you ask for a person', async () => {
let query = `
query {
person {
name
}
}
`;
let { data } = await graphql(schema, query)
expect(data.person).toEqual({name: 'Mike'})
})
})
This test passes which tells us that we got everything wired together properly, and the foundation laid to talk to ArangoDB.
First we’ll use arangojs and create a db instance and then a function that allows us to get a person using their name.
//src/database.js
import arangojs, { aql } from 'arangojs'
export const db = arangojs({
url: `http://${process.env.ARANGODB_USER}:${process.env.ARANGODB_PASSWORD}@127.0.0.1:8529`,
databaseName: 'knows'
})
export async function getPersonByName (name) {
let query = aql`
FOR person IN persons
FILTER person.name == ${ name }
LIMIT 1
RETURN person
`
let results = await db.query(query)
return results.next()
}
Now lets use that function with our schema to retrieve real data from ArangoDB.
import {
graphql,
GraphQLSchema,
GraphQLObjectType,
GraphQLString,
GraphQLList,
GraphQLNonNull
} from 'graphql'
import {
db,
getPersonByName
} from '../src/database'
describe('queries', () => {
it('lets you ask for a person from the database', async () => {
let Person = new GraphQLObjectType({
name: 'Person',
fields: () => ({
name: {
type: GraphQLString
}
})
})
let schema = new GraphQLSchema({
query: new GraphQLObjectType({
name: 'Query',
fields: () => ({
person: {
args: { //person now accepts args
name: { // the arg is called "name"
type: new GraphQLNonNull(GraphQLString) // name is a string & manadatory
}
},
type: Person,
resolve: (root, args) => {
return getPersonByName(args.name)
},
}
})
})
})
let query = `
query {
person(name "Eve") {
name
}
}
`
let { data } = await graphql(schema, query)
expect(data.person).toEqual({name: 'Eve'})
})
})
Here we have modified our schema to accept a name argument when asking for a person. We access the name via the args object and pass it to our database function to go get the matching person from Arango.
Let’s add a new database function to get the friends of a user given their id.
What’s worth pointing out here is that we are using ArangoDB’s AQL traversal syntax. It allows us to do a graph traversal across outbound edges get the vertex on the other end of the edge.
export async function getFriends (id) {
let query = aql`
FOR vertex IN OUTBOUND ${id} knows
RETURN vertex
`
let results = await db.query(query)
return results.all()
}
Now that we have that function, instead of adding it to the schema, we add a field to the Person type. In the resolve for our new friends field we are going to use the root argument to get the id of the current person object and then use our getFriends function to do the traveral to retrieve the persons friends.
let Person = new GraphQLObjectType({
name: 'Person',
fields: () => ({
name: {
type: GraphQLString
},
friends: {
type: new GraphQLList(Person),
resolve(root) {
return getFriends(root._id)
}
}
})
})
What’s interesting is that because of GraphQL’s recursive nature, this change lets us query for friends:
query {
person(name: "Eve") {
name
friends {
name
}
}
}
and also ask for friends of friends (and so on) like this:
query {
person(name: "Eve") {
name
friends {
name
friends {
name
}
}
}
}
We can show that with a test.
import {
graphql,
GraphQLSchema,
GraphQLObjectType,
GraphQLString,
GraphQLList,
GraphQLNonNull
} from 'graphql'
import {
db,
getPersonByName,
getFriends
} from '../src/database'
describe('queries', () => {
it('returns friends of friends', async () => {
let Person = new GraphQLObjectType({
name: 'Person',
fields: () => ({
name: {
type: GraphQLString
},
friends: {
type: new GraphQLList(Person),
resolve(root) {
return getFriends(root._id)
}
}
})
})
let schema = new GraphQLSchema({
query: new GraphQLObjectType({
name: 'Query',
fields: () => ({
person: {
args: {
name: {
type: new GraphQLNonNull(GraphQLString)
}
},
type: Person,
resolve: (root, args) => {
return getPersonByName(args.name)
},
}
})
})
})
let query = `
query {
person(name: "Eve") {
name
friends {
name
friends {
name
}
}
}
}
`
let result = await graphql(schema, query)
let { friends } = result.data.person
let foaf = [].concat(...friends.map(friend => friend.friends))
expect([{name: 'Charlie'},{name: 'Dave'},{name: 'Bob'}]).toEqual(expect.arrayContaining(foaf))
})
})
This test has running a query three levels deep and walking the entire graph. Because we can ask for any combination of any of the things our types defined, we have a whole lot of flexibility with very little code. The code that’s there is just a few simple functions, modular and easy to test.
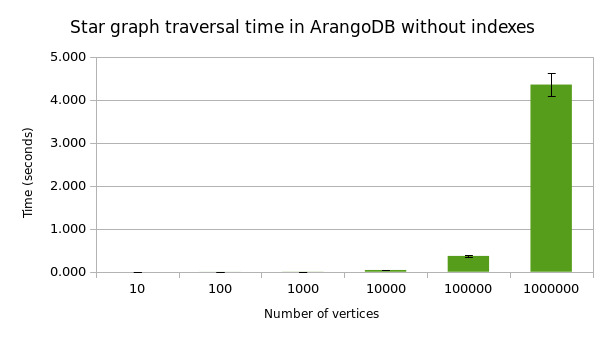
But what did we trade away to get all that? If we look at the queries that get sent to Arango with tcpdump we can see how that sausage was made.
// getPersonByName('Eve') from the person resolver in our schema
{"query":"FOR person IN persons
FILTER person.name == @value0
LIMIT 1 RETURN person","bindVars":{"value0":"Eve"}}
// getFriends('persons/eve') in Person type -> returns Bob & Alice.
{"query":"FOR vertex IN OUTBOUND @value0 knows
RETURN vertex","bindVars":{"value0":"persons/eve"}}
// now a new request for each friend:
// getFriends('persons/bob')
{"query":"FOR vertex IN OUTBOUND @value0 knows
RETURN vertex","bindVars":{"value0":"persons/bob"}}
// getFriends('persons/alice')
{"query":"FOR vertex IN OUTBOUND @value0 knows
RETURN vertex","bindVars":{"value0":"persons/alice"}}
What we have here is our own version of the famous N+1 problem. If we were to add more people to this graph things would get out of hand quickly.
Facebook, which has been using GraphQL in production for years, is probably even less excited about the prospect of N+1 queries battering their database than we are. So what are they doing to solve this?
Using Dataloader
Dataloader is a small library released by Facebook that solves the N+1 problem by cleverly leveraging the way promises work. To use it, we need to give it a batch loading function and then replace our calls to the database with calls call Dataloader’s load method in all our resolves.
What, you might ask, is a batch loading function? The dataloader documentation offers that “A batch loading function accepts an Array of keys, and returns a Promise which resolves to an Array of values.”
We can write one of those.
async function getFriendsByIDs (ids) {
let query = aql`
FOR id IN ${ ids }
let friends = (
FOR vertex IN OUTBOUND id knows
RETURN vertex
)
RETURN friends
`
let response = await db.query(query)
return response.all()
}
We can then use that in a new test.
import {
graphql
} from 'graphql'
import DataLoader from 'dataloader'
import {
db,
getFriendsByIDs
} from '../src/database'
import schema from '../src/schema'
describe('Using dataloader', () => {
it('returns friends of friends', async () => {
let Person = new GraphQLObjectType({
name: 'Person',
fields: () => ({
name: {
type: GraphQLString
},
friends: {
type: new GraphQLList(Person),
resolve(root, args, context) {
return context.FriendsLoader.load(root._id)
}
}
})
})
let query = `
query {
person(name: "Eve") {
name
friends {
name
friends {
name
}
}
}
}
`
const FriendsLoader = new DataLoader(getFriendsByIDs)
let result = await graphql(schema, query, {}, { FriendsLoader })
let { person } = result.data
expect(person.name).toEqual('Eve')
expect(person.friends.length).toEqual(2)
let names = person.friends.map(friend => friend.name)
expect(names).toContain('Alice', 'Bob')
})
})
The key section of the above test is this:
const FriendsLoader = new DataLoader(getFriendsByIDs)
// schema, query, root, context
let result = await graphql(schema, query, {}, { FriendsLoader })
The context object is passed as the fourth parameter to the graphql function which is then available as the third parameter in every resolve function. With our FriendsLoader attached to the context object, you can see us accessing it in the resolve function on the Person type.
Let’s see what effect that batch loading has on our queries.
// getPersonByName('Eve') from the person resolver in our schema
{"query":"FOR person IN persons
FILTER person.name == @value0
LIMIT 1 RETURN person","bindVars":{"value0":"Eve"}}
// getFriendsByIDs(["persons/eve"]) -> returns Bob & Alice.
{"query":"FOR id IN @value0
let friends = (
FOR vertex IN OUTBOUND id knows
RETURN vertex
)
RETURN friends","bindVars":{"value0":["persons/eve"]}}
// getFriendsByIDs(["persons/alice","persons/bob"])
{"query":"FOR id IN @value0
let friends = (
FOR vertex IN OUTBOUND id knows
RETURN vertex
)
RETURN friends","bindVars":{"value0":["persons/alice","persons/bob"]}}
Now for a three level query (Eve, her friends, their friends) we are down to just 1 query per level and the N+1 problem is no longer a problem.
When it’s time to serve your data to the world, express-graphql supplies a middleware that we can pass our schema and loaders to like this:
import express from 'express'
import graphqlHTTP from 'express-graphql'
import schema from './schema'
import DataLoader from 'dataloader'
import { getFriendsByIDs } from '../src/database'
const FriendsLoader = new DataLoader(getFriendsByIDs)
const app = express()
app.use('/graphql', graphqlHTTP({ schema, context: { FriendsLoader }}))
app.listen(3000)
// http://localhost:3000/graphql is up and running!
What we just did
With just those few code examples we’ve built a backend system that provides a query-able API for clients backed by a graph database. Growing it would look like adding a few more functions and a few more types. The code stays modular and testable. Dataloader has ensured that we didn’t even pay a performance penalty for that.
A perfect combination
While geeking out on the technology is fun, it loses sight of what I think is the larger point: The design of both GraphQL and ArangoDB allow you to combine and recombine some really simple primitives to tackle anything you can think of.
With ArangoDB, it’s all just documents, whether you use them like that or treat them as key/value or a graph is up to you. While this approach is marketed as “multi-model” database, the term is unfortunate since it makes the database sound like it’s trying to do lots of things instead of leveraging some fundamental similarity between these types of data. That similarity becomes the “primitive” that makes all this flexibility possible.
For GraphQL, my application is just a bunch of functions in an Abstract Syntax Tree which get combined and recombined by client queries. The parser and execution engine take care of what gets called when.
In each case what I need to understand is simple, the behaviour I can produce is complex.
I’m still honing my minimal set for front end development, but for backend development this is now how I build. These days I’m refocusing my learning to go narrow and deep and it feels good. Infinite width never felt sustainable. It’s not apparent at first, but once that burden is lifted off your shoulders you will realize how heavy it was.