ArangoDB’s AQL query language was created to offer a unified interface for working with key/value, document and graph data. While AQL has been easy to work with and learn, it wasn’t until the addition of AQL traversals in ArangoDB 2.8 that it really felt like it has achieved it’s goal.
Adding keywords GRAPH, OUTBOUND, INBOUND and ANY suddenly made iteration using a FOR loop the central idea in the language. This one construct can now be used to iterate over everything; collections, graphs or documents:
//FOR loops for everything
FOR person IN persons //collections
FOR friend IN OUTBOUND person GRAPH "knows_graph" //graphs
FOR value in VALUES(friend, true) //documents
RETURN DISTINCT value
AQL has always felt more like programming than SQL ever did, but the central role of the FOR loop gives a clarity and simplicity that makes AQL very nice to work with. While this is a great addition to the language, it does however, mean that there are now 4 different ways to traverse a graph in AQL and a few things are worth pointing out about the differences between them.
AQL Traversals
There are two variations of the AQL traversal syntax; the named graph and the anonymous graph. The named graph version uses the GRAPH keyword and a string indicating the name of an existing graph. With the anonymous syntax you can simply supply the edge collections
//Passing the name of a named graph FOR vertex IN OUTBOUND "persons/eve" GRAPH "knows_graph" //Pass an edge collection to use an anonymous graph FOR vertex IN OUTBOUND "persons/eve" knows
Both of these will return the same result. The traversal of the named graph uses the vertex and edge collections specified in the graph definition, while the anonymous graph uses the vertex collection names from the _to/_from attributes of each edge to determine the vertex collections.
If you want access to the edge or the entire path all you need to do is ask:
FOR vertex IN OUTBOUND "persons/eve" knows FOR vertex, edge IN OUTBOUND "persons/eve" knows FOR vertex, edge, path IN OUTBOUND "persons/eve" knows
The vertex, edge and path variables can be combined and filtered on to do some complex stuff. The Arango docs show a great example:
FOR v, e, p IN 1..5 OUTBOUND 'circles/A' GRAPH 'traversalGraph' FILTER p.edges[0].theTruth == true AND p.edges[1].theFalse == false FILTER p.vertices[1]._key == "G" RETURN p
Notes
Arango can end up doing a lot of work to fill in those FOR v, e, p IN variables. ArangoDB is really fast, so to show the effect these variables can have, I created the most inefficient query I could think of; a directionless traversal across a high degree vertex with no indexes.
The basic setup looked like this except with 10000 vertices instead of 10. The test was getting from start across the middle vertex to end.

What you can see is that adding those variables comes at a cost, so only declare ones you actually need.

GRAPH_* functions and TRAVERSAL
ArangoDB also has a series of “Named Operations” that feature among
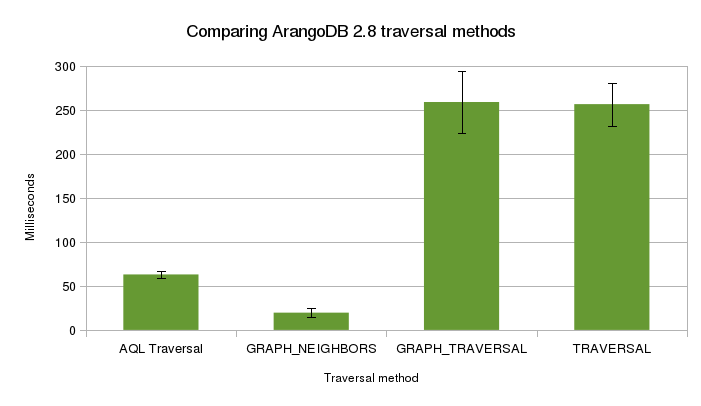
them a few that also do traversals. There is also a super old-school TRAVERSAL function hiding in the “Other” section. What’s interesting is how different their performance can be while still returning the same results.
I tested all of the traversal functions on the same supernode described above. These are the queries:
//AQL traversal
FOR v IN 2 ANY "vertices/1" edges
FILTER v.name == "end"
RETURN v
//GRAPH_NEIGHBORS
RETURN GRAPH_NEIGHBORS("db_10000", {_id: "vertices/1"}, {direction: "any", maxDepth:2, includeData: true, neighborExamples: [{name: "end"}]})
//GRAPH_TRAVERSAL
RETURN GRAPH_TRAVERSAL("db_10000", {_id:"vertices/1"}, "any", {maxDepth:2, includeData: true, filterVertices: [{name: "end"}], vertexFilterMethod: ["exclude"]})
//TRAVERSAL
RETURN TRAVERSAL(vertices, edges, {_id: "vertices/1"}, "any", {maxDepth:2, includeData: true, filterVertices: [{name: "end"}], vertexFilterMethod: ["exclude"]})
All of these returned the same vertex, just with varying levels of nesting within various arrays. Removing the nesting did not make a signficant difference in the execution time.
Notes
While TRAVERSAL and GRAPH_TRAVERSAL were not stellar performers here, the both have a lot to offer in terms of customizability. For ordering, depthfirst searches and custom expanders and visitors, this is the place to look. As you explore the options, I’m sure these get much faster.
Slightly less obvious but still worth pointing out that where AQL traversals require an id (“vertices/1000” or a document with and _id attribute), GRAPH_* functions just accept an example like {foo: “bar”} (I’ve passed in {_id: “vertices/1”} as the example just to keep things comparable). Being able to find things, without needing to know a specific id, or what collection to look in is very useful. It lets you abstract away document level concerns like collections and operate on a higher “graph” level so you can avoid hardcoding collections into your queries.
What it all means
The difference between these, at least superficially, similar traversals are pretty surprising. While some where faster than others, none of the options for tightening the scope of the traversal were used (edge restrictions, indexes, directionality). That tells you there is likely a lot of headroom for performance gains for all of the different methods.
The conceptual clarity that AQL traversals bring to the language as a whole is really nice, but it’s clear there is some optimization work to be done before I go and rewrite all my queries.
Where I have used the new AQL traversal syntax, I’m also going to have to check to make sure there are no unused v,e,p variables hiding in my queries. Where you need to use them, it looks like restricting yourself to v,e is the way to go. Generating those full paths is costly. If you use them, make sure it’s worth it.
Slowing Arango down is surprisingly instructive, but with 3.0 bringing the switch to Velocypack for JSON serialization, new indexes, and more, it looks like it’s going to get harder to do. :)

