Enterprise architecture (EA) is a troublesome discipline. I think it’s fair to argue that the famous Bezos API mandate and the birth of AWS are both essentially enterprise architecture efforts as is Simian Army from Netflix. These efforts have clearly delivered a huge positive business impact, but it’s much harder to make that case for the version of EA that exists in government.
For this government version, if we look beyond the tendencies towards self-referential documentation, and the use of frameworks that lack empirical grounding, there is an increasingly visible conflict with a growing body of knowledge about risk and resilience that is worth considering.
In Canada, Treasury Boards Policy on Service and Digital requires the GC CIO to define an enterprise architecture while the Directive on Service and Digital requires the departmental CIOs to “align” with it.
EA is used to design a target architecture, but more people are familiar with it as a project gating mechanism where the pressure to “align” is applied to projects. Mostly this takes the form of EA arguing for centralization and deduplication largely justified by cost savings.
This focus stands in sharp contrast with the literature on resilience, which largely views this sort of cost-optimization activity as stripping a system of it’s adaptive capacity.
What’s common to all of these approaches- robustness, redundancy, and resilience, especially through diversity and decentralization- is that they are not efficient. Making systems resilient is fundamentally at odds with optimization, because optimizing a system means taking out any slack.
Deb Chachra, How Infrastructure Works
Since this stuff can feel pretty abstract, we can try to make this concrete with a look at Treasury Board’s Sign-in-Canada service which is a key part of their “target enterprise architecture”.
The Government of Canada has ~208 Departments and Agencies, 86 of which have their own accounts. This is often held up as an example of of inefficiency and duplication, and the kind of thing that EA exists to fix. As TBS describes: “Sign‑in Canada is a proposal for a unified authentication mechanism for all government digital engagement with citizens.”
If you skip past the meetings required to get all 86 systems to use Sign-in-Canada, the end result would be a “star graph” style architecture; Sign-in-Canada in the center, with digital services connecting to it.
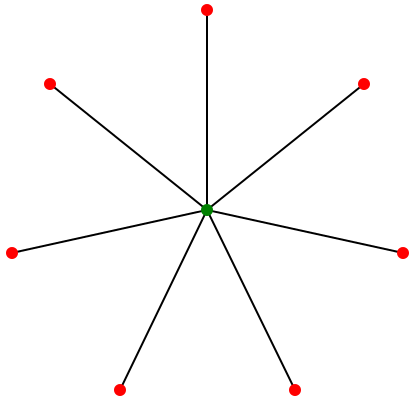
Prized for efficiency and especially for central control this star-graph style architecture shows up everywhere in governments. To get to this architecture, EA practitioners apply steady pressure in those meetings (those gating functions of Enterprise Architecture Review Boards) to avoid new sign-in systems and ensure new and existing systems connect to/leverage Sign-in-Canada.
In graph theory there is a term for networks that are formed under such conditions; “preferential attachment“, where new “nodes” in the network attach to existing popular nodes.
Networks formed under a preferential attachment model (called “scale-free” in the literature) have some really interesting (and well studied) properties that I think are exactly what EA is trying to encourage; networks formed like this are surprisingly robust to random failures.
If you imagine the power/cooling/rack space constraints of a traditional data center, and the challenge of staying within those limits while limiting the effects of random failures, the centralization/deduplication focus of EA is a huge benefit.
But “scale-free” networks also have another property: They are very fragile to targeted attack. Only a handful of highly connected nodes need to be removed before the network is completely destroyed. If targeted attacks are suddenly the concern, the preferential attachment playbook, starts to look like a problem rather than a solution.
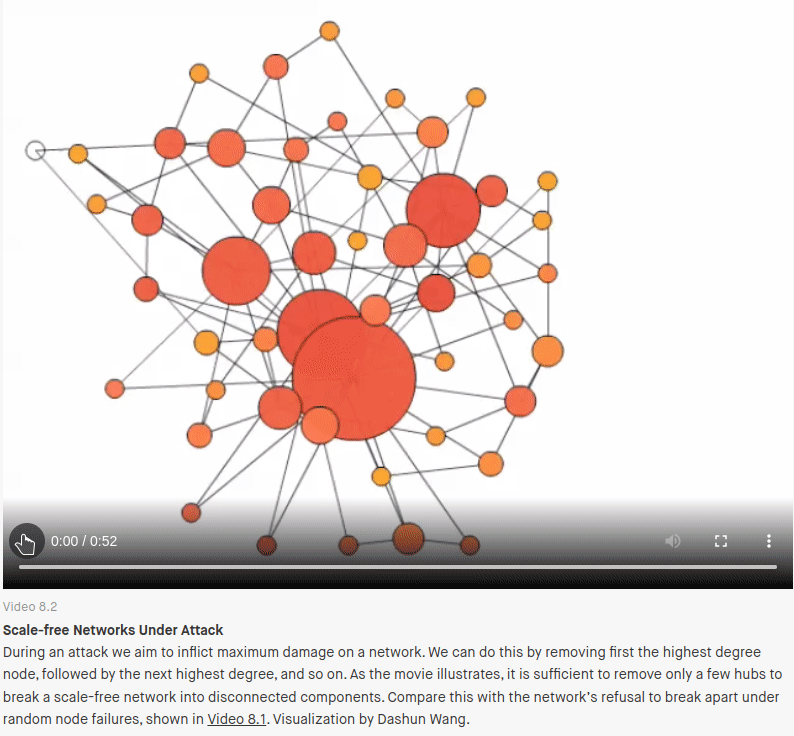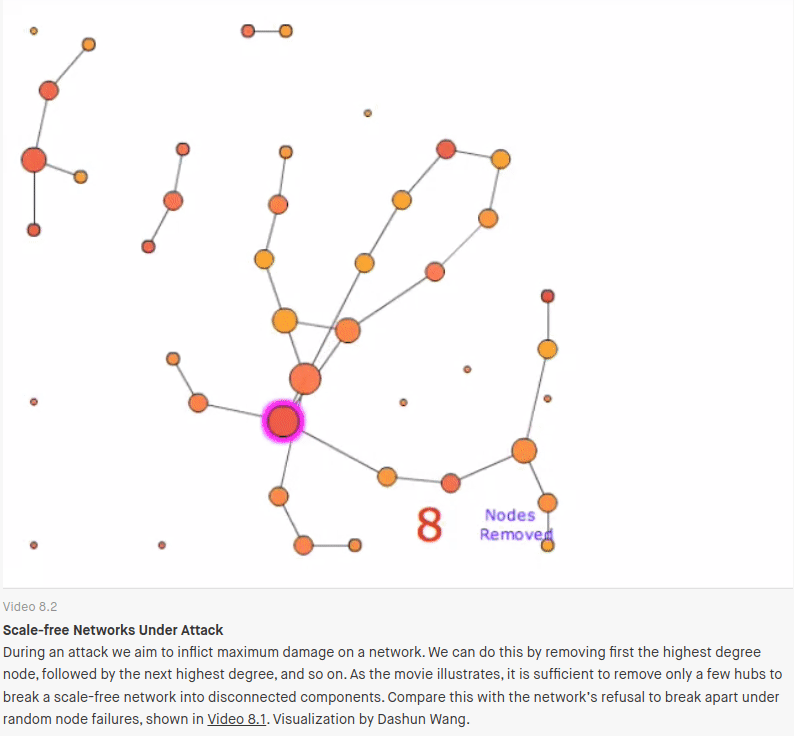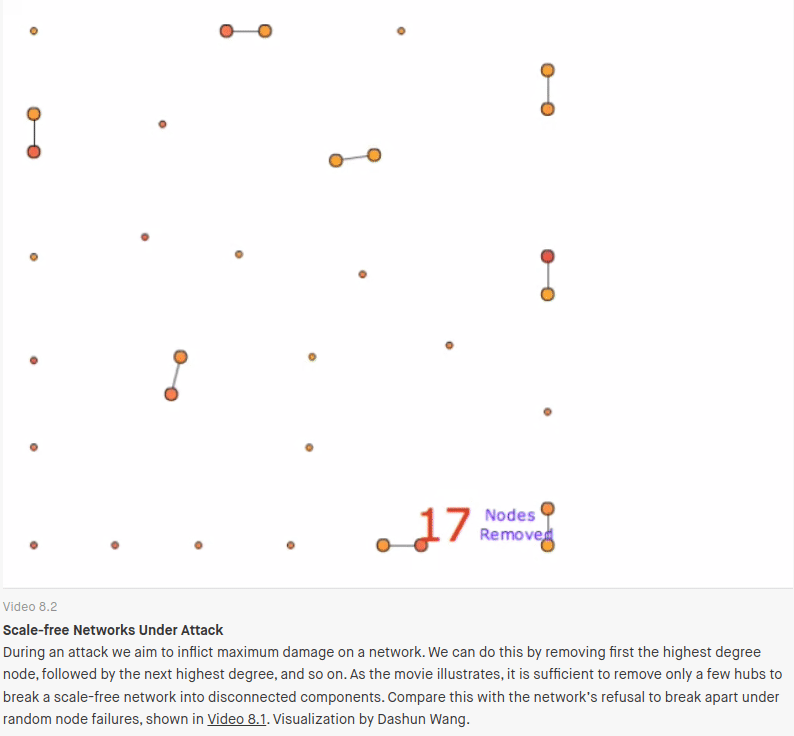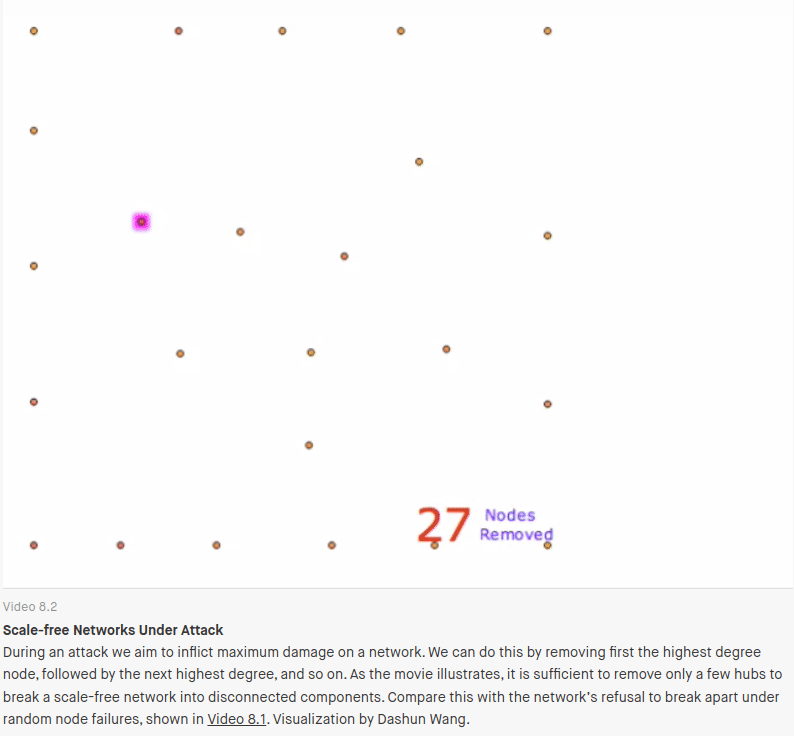
It’s these ideas that show why an EA practice narrowly focused on reuse/centralization/deduplication ends up conflicting with resilience engineering and modern security architecture.
Through that resilience lens, the success of Sign-in-Canada means a successful hack (the Okta breach gives us a preview) could paralyze 86 government organizations, something that isn’t currently possible.
In academic terms what we’ve done is increase our systems “fragility”, it’s a well known byproduct of the kinds of optimizations that EA is tasked with making.
We need to understand that this mechanistic goal of optimization as creating this terrible fragility and that we need to try and think about how we can mitigate against this.
Paul Larcey: Illusion of Control 2023
These system/network properties are well known enough that the US military has developed an algorithm that will induce fragility in human organizations. It uses this to make networks (terror networks in their case) more vulnerable to targeted attack.
The algorithm is called “greedy fragile” and it works by selecting nodes for “removal” via “shaping operations” (you can imagine what removing someone from a social network means in a military context), so that the resulting network is more centralized (“star-like”) and fragile; centralizing as a way maximize the impact of a future attack.

While it might sound uncharitable to lay the responsibility for systemic fragility at the feet of enterprise architecture it is literally the mandate of these groups to identify and make many of these optimizations happen. It’s worth saying the executives fixated on centralization and security’s penchant for highly centralized security “solutions” are big contributors too.
I would argue the 2022 hack of Global Affairs which brought down the entire department for over a month is an example of of this fragility. When an entire department can fail as a single unit, this is an architectural failure as much as it is a security failure; one that says a lot about the level of centralization involved.
It’s worth saying that architecting for resilience definitely still counts as “enterprise architecture”, and in that way I think EA is actually more important than ever. However as pointed out in How infrastructure Works, it would be a big shift from current practice.
“Designing infrastructural systems for resilience rather than optimizing them for and efficiency is an epistemological shift”
Deb Chachra, How Infrastructure Works
We very much need EA teams (and security architecture teams) to make that shift to focusing on resilience. The EA folks I’ve met are brilliant analysts and more than capable of updating their playbooks with ideas from complex systems, cell-based architecture, resilience patterns like the bulkhead pattern, chaos engineering, or Team-Topologies and using them to build more resilient architectures at every level: both system and organizational.
With Global Affairs, FINTRAC and RCMP all hit within a few weeks of each other here in early 2024, making resilience a priority across the government is crucial and there is nobody better placed to do that than enterprise architects.



