Since 2009 there has been a “Cambrian Explosion” of NoSQL databases, but information on data modeling with these new data stores feels hard to come by.
My weapon of choice for over a year now has been ArangoDB. While ArangoDB is pretty conscientious about having good documentation, there has been something missing for me: criteria for making modeling decisions.
Like most (all?) graph databases, ArangoDB allows you to model your data with a property graph. The building blocks of a property graph are attributes, vertices and edges. What makes data modelling with ArangoDB (and any other graph database) difficult is deciding between them.
To start with we need a little terminology. Since a blog is a well known thing, we can use a post with some comments and some tags as our test data to illustrate the idea.
Sparse vs Compact
Modeling our blog post with as a “sparse” graph might look something like this:
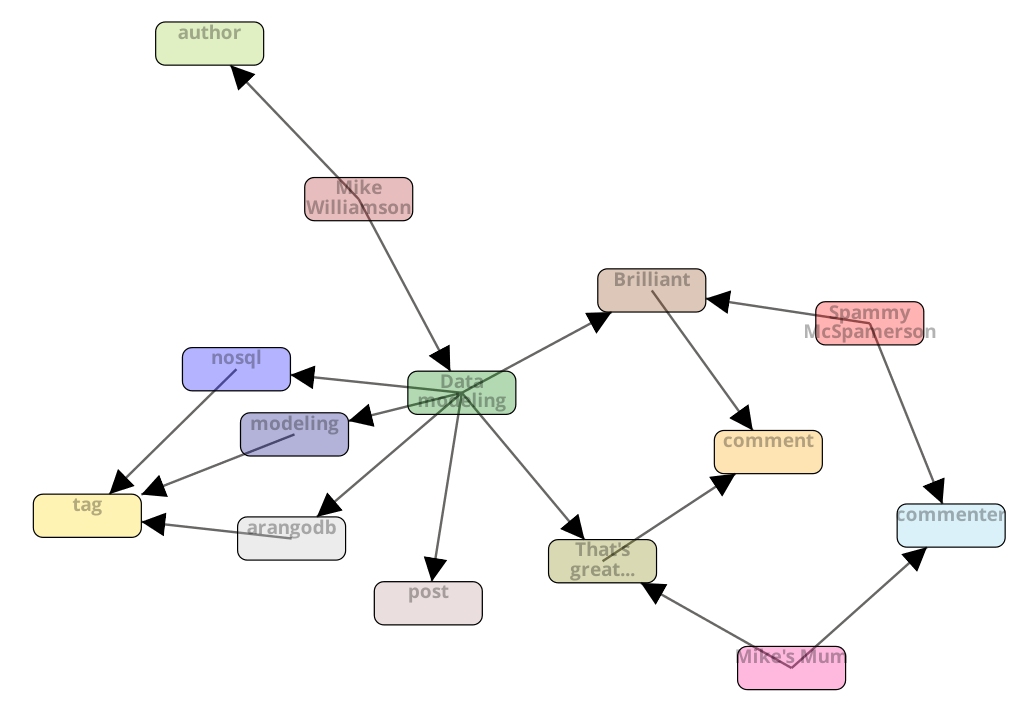
At first glance it looks satisfyingly graphy: in the centre we see a green “Data Modeling” vertex which has a edge going to another vertex “post”, indicating that “Data Modeling” is a post. Commenters, tags and comments all have connections to a vertex representing their type as well.
Looking at the data you can see we are storing lots of edges and most vertices contain only a single attribute (apart from the internal attributes ArangoDB creates: _id, _key, _rev).
//vertices
{"_id":"vertices/26590247555","_key":"26590247555","_rev":"26590247555","title":"That's great honey","text":"Love you!"},
{"_id":"vertices/26590378627","_key":"26590378627","_rev":"26590378627","type":"comment"},
{"_id":"vertices/26590509699","_key":"26590509699","_rev":"26590509699","name":"Spammy McSpamerson","email":"spammer@fakeguccihandbags.com"},
{"_id":"vertices/26590640771","_key":"26590640771","_rev":"26590640771","title":"Brilliant","text":"Gucci handbags..."},
{"_id":"vertices/26590771843","_key":"26590771843","_rev":"26590771843","name":"arangodb"},
{"_id":"vertices/26590902915","_key":"26590902915","_rev":"26590902915","name":"modeling"},
{"_id":"vertices/26591033987","_key":"26591033987","_rev":"26591033987","name":"nosql"},
{"_id":"vertices/26591165059","_key":"26591165059","_rev":"26591165059","type":"tag"}]
//edges
[{"_id":"edges/26604010115","_key":"26604010115","_rev":"26604010115","_from":"vertices/26589723267","_to":"vertices/26589395587"},
{"_id":"edges/26607352451","_key":"26607352451","_rev":"26607352451","_from":"vertices/26589723267","_to":"vertices/26589854339"},
{"_id":"edges/26608204419","_key":"26608204419","_rev":"26608204419","_from":"vertices/26590640771","_to":"vertices/26590378627"},
{"_id":"edges/26609842819","_key":"26609842819","_rev":"26609842819","_from":"vertices/26590247555","_to":"vertices/26590378627"},
{"_id":"edges/26610694787","_key":"26610694787","_rev":"26610694787","_from":"vertices/26589985411","_to":"vertices/26590247555"},
{"_id":"edges/26611546755","_key":"26611546755","_rev":"26611546755","_from":"vertices/26589395587","_to":"vertices/26590247555"},
{"_id":"edges/26615020163","_key":"26615020163","_rev":"26615020163","_from":"vertices/26589985411","_to":"vertices/26590116483"},
{"_id":"edges/26618821251","_key":"26618821251","_rev":"26618821251","_from":"vertices/26590771843","_to":"vertices/26591165059"},
{"_id":"edges/26622622339","_key":"26622622339","_rev":"26622622339","_from":"vertices/26589395587","_to":"vertices/26589592195"},
{"_id":"edges/26625833603","_key":"26625833603","_rev":"26625833603","_from":"vertices/26590509699","_to":"vertices/26590640771"},
{"_id":"edges/26642741891","_key":"26642741891","_rev":"26642741891","_from":"vertices/26589395587","_to":"vertices/26590902915"},
{"_id":"edges/26645101187","_key":"26645101187","_rev":"26645101187","_from":"vertices/26589395587","_to":"vertices/26590771843"},
{"_id":"edges/26649885315","_key":"26649885315","_rev":"26649885315","_from":"vertices/26589395587","_to":"vertices/26591033987"},
{"_id":"edges/26651064963","_key":"26651064963","_rev":"26651064963","_from":"vertices/26590902915","_to":"vertices/26591165059"},
{"_id":"edges/26651785859","_key":"26651785859","_rev":"26651785859","_from":"vertices/26591033987","_to":"vertices/26591165059"},
{"_id":"edges/26652965507","_key":"26652965507","_rev":"26652965507","_from":"vertices/26590509699","_to":"vertices/26590116483"},
{"_id":"edges/26670267011","_key":"26670267011","_rev":"26670267011","_from":"vertices/26589395587","_to":"vertices/26590640771"}]
A “compact” graph on the other hand might look something like this:
{
title: "Data modelling",
text: "lorum ipsum...",
author: "Mike Williamson",
date: "2015-11-19",
comments: [
{
author:"Mike's Mum",
email:"mikes_mum@allthemums.com",
text: "That's great honey",
},
{
"author": "spammer@fakeguccihandbags.com",
"title": "Brilliant",
"text": "Gucci handbags...",
}
],
tags:["mongodb","modeling","nosql"]
}
Here we have taken exactly the same data and collapsed it together into a single document. While its a bit of a stretch to even classify this as a graph, ArangoDB’s multi-model nature largely erases the boundary between a document and a graph with a single vertex.
The two extremes above give us some tools for talking about our graph. Its the same data either way, but clearly different choices are being made. In the sparse graph, every vertex you see could have been an attribute, but was consciously moved into a vertex of its own. The compact graph is what comes out of repeated choosing to add new data as an attribute rather than a vertex.
When modeling real data your decisions don’t always fall one one side or the other. So what criteria should we be using to make those decisions?
Compact by default
As a baseline you should favor a compact graph. Generally data that is displayed together should be combined into a single document.
Defaulting to compact will mean fewer edges will exist in the graph as a whole. Since each traversal across a graph will have to find, evaluate and then traverse the edges for each vertex it encounters, keeping the number of edges to a strict minimum will ensure traversals stay fast as your graph grows.
Compact graphs will also mean fewer queries and traversals to get the information you need. When in doubt, embed. Resist the temptation to add vertices just because it’s a graph database, and keep it compact.
But not everything belongs together. Any attribute that contains a complex data structure (like the “comments” array or the “tags” array) deserves a little scrutiny as it might make sense as a vertex (or vertices) of its own.
Looking at our compact graph above, the array of comments, the array of tags, and maybe even the author might be better off as vertices rather than leaving them as attributes. How do we decide?
- Will it be accessed on it’s own? (ie: showing comments without the post)
- Will you be running a graph measurement (like GRAPH_BETWEENNESS) on it?
- Will it be edited on it’s own?
- Does/could the attribute have relationships of it’s own? (assuming you care)
- Would/should this attribute exist without it’s parent vertex?
Removing duplicate data can also be a reason to make something a vertex, but with the cost of storage ridiculously low (and dropping) its a weak reason. Finding yourself updating duplicate data however, tells you that it should have been a vertex.
Edge Direction
Once you promote a piece of data to being a vertex (or “reify” it) your next decision is which way the edge connecting it to another vertex should go. Edge direction is a powerful way to put up boundaries to contain your traversals, but while the boundary is important the actual directions are not. Whatever you choose, it just needs to be consistent. One edge going the wrong direction is going to have your traversal returning things you don’t expect.
And another thing…
This post is the post I kept hoping to find as I worked on modeling my data with ArangoDB. Its not complete, data modeling is a big topic and there is lots more depth to ArangoDB to explore (ie: I haven’t yet tried splitting my edges amongst multiple edge collections) but these are some guidelines that I was hoping for when I was starting.
I would love to learn more about the criteria people are using to make those tough calls between attribute and vertex, and all those other hard modeling decisions.
If you have thoughts on this let me know!

Reblogged this on G O T I U M.
Nice post. Can I add two additional guidelines that I have found useful in the past?
1) If two entities have different lifetimes, they should be different vertices. E.g. a comment will usually be created later and may be deleted earlier that the post, so the comment should be a separate vertex.
2) If two entities have different permissions, they should be different vertices. E.g. I may have permission to edit or delete my comment, but certainly not your article, so the comment should be a separate vertex.
Sidenote: If I had permission to edit your article I would change “multi-modal” to “multi-model”. ArangoDB is multi-model, because it allows you to model your data with documents, graphs, key-value models. But it is not multi-modal, because you don’t have to switch between modes. ;-)
cheers, martin